Chapter 2
A Tour of Rust: The Basics
“The art of programming is the art of organizing complexity, of mastering multitude and avoiding its bastard chaos as effectively as possible.” — Edsger W. Dijkstra
Chapter 2 of TRPL - “A Tour of Rust - The Basics" lays the groundwork for a comprehensive understanding of Rust's core principles. It starts with simple examples like "Hello, World!" and covers fundamental topics such as types, variables, and arithmetic operations. The chapter then explains the roles of constants, tests, and loops, and introduces pointers, arrays, and loops with detailed examples showcasing their usage. It delves into user-defined types, including structures, classes, and enumerations, highlighting their contribution to Rust's powerful and expressive type system. Emphasizing modularity, the chapter covers separate compilation, namespaces, and error handling, essential for effectively organizing and managing Rust programs. It concludes with a postscript and practical advice, offering readers valuable insights and best practices for mastering and applying Rust in their programming endeavors.
2.1. Introduction
The aim of this chapter and the next three is to give you an idea of what Rust is, without going into a lot of details. This chapter informally presents Rust's syntax, its memory and computation model, and the basic mechanisms for organizing code into a program. These are the language facilities supporting procedural programming styles. Chapter 3 will build on this by introducing Rust's abstraction mechanisms.
The assumption is that you have programmed before. If not, please consider reading a textbook, such as The C Programming Language by Kernighan and Ritchie, before continuing here. Even if you have programmed before, the language you used or the applications you wrote may be very different from the style of Rust presented here.
This tour of Rust saves us from a strictly bottom-up presentation of language and library features by enabling the use of a rich set of facilities even in early chapters. For example, loops are not discussed in detail until later, but they will be used in straightforward ways long before that. Similarly, the detailed descriptions of structs, enums, ownership, and the standard library are spread over many chapters, but standard library types, such as Vec, String, Option, Result, Box, and std::io, are used freely where needed to enhance code examples.
Imagine this as a short sightseeing tour of a city like Jakarta or Singapore. In just a few hours, you get a quick glimpse of the major attractions, hear some background stories, and receive suggestions on what to explore next. You won't fully understand the city after such a tour, nor will you grasp everything you've seen and heard. To truly know a city, you need to live in it, often for years. Similarly, this overview of Rust gives you a brief introduction, showcasing what makes Rust special and what might interest you. After this initial tour, the real exploration begins.
This tour presents Rust as an integrated whole rather than a collection of separate layers. It doesn't differentiate between features from earlier versions of Rust and those introduced in newer editions. Instead, it offers a cohesive view of Rust, showing how its various elements work together to create a powerful and efficient programming language.
2.2. The Basics
Rust is a compiled language, meaning that its source code needs to be processed by a compiler to create a runnable program. You write your Rust code in one or more source files, commonly named Main.rs and Lib.rs. The Rust compiler processes these source files to produce object files, such as Main.o and Lib.o. These object files are then combined by a linker to create the final executable program. This process ensures that all parts of your program are correctly compiled and linked together, resulting in a file that you can run on your computer.
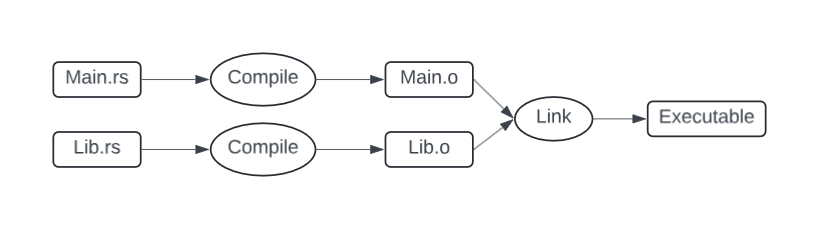
Figure 1: Separate compilation using rustc compiler.
When we talk about the portability of Rust programs, we refer to the ability of Rust’s source code to be compiled and run on different systems. It’s important to note that the compiled executable is specific to the hardware and operating system it was built for. For instance, an executable built on a Mac will not run on a Windows PC without recompilation. However, the same Rust source code can be compiled on different systems, such as Mac, Windows, and Linux, to produce executables for those systems.
To compile Rust source files Main.rs and Lib.rs into object files and then link them into a final executable, you need to use the rustc command-line tool.
rustc --emit=obj -o Main.o Main.rs
The --emit=obj flag instructs the Rust compiler to produce an object file rather than an executable. The -o flag specifies the name of the output file, which in this case is Main.o. Similarly, compile Lib.rs into an object file named Lib.o using this command:
rustc --emit=obj -o Lib.o Lib.rs
Again, --emit=obj tells the compiler to create an object file, and -o specifies the output file name, Lib.o. Here, rustc takes the two object files, Main.o and Lib.o, and the following command links them together to generate an executable named MyProgram.
rustc Main.o Lib.o -o MyProgram
These commands should be executed in your VS Code terminal or command prompt from the directory where your source files are located. By following these steps, you compile and link your Rust code into a runnable program. Another technique for compiling a library is using the cargo tool and compiler option --crate-type=lib. You can practice this later using ChatGPT.
Rust’s standard defines two main types of entities: core language features and standard library components. Core language features include built-in types like char and i32, as well as control flow constructs like for loops and while loops. These features are intrinsic to the language and provide the basic building blocks for writing Rust programs. Standard library components are additional tools provided by Rust’s standard library, such as collections (Vec and HashMap) and I/O operations (println! and read_line()). The standard library is implemented in Rust itself, with minimal machine code used for low-level tasks like thread context switching. This showcases Rust’s capability to handle even the most demanding systems programming tasks efficiently.
The standard library components in Rust are ordinary Rust code provided by every Rust implementation. In fact, the Rust standard library can be implemented in Rust itself, with minimal use of machine code for tasks such as thread context switching. This demonstrates that Rust is sufficiently expressive and efficient for the most demanding systems programming tasks.
Rust is a statically typed language, which means that the type of every variable, value, name, and expression must be known at compile time. This ensures that types are checked before the program runs, enhancing both safety and performance. The type of an entity determines what operations can be performed on it, ensuring that you can't accidentally misuse data in ways that could cause errors or crashes. By understanding these concepts, you can better appreciate how Rust ensures reliability and efficiency in systems programming.
2.3. Hello, World!
The minimal Rust program is:
fn main() {}
// the minimal Rust program
This defines a function called \main\, which takes no arguments and does nothing. Curly braces \{}\ are used to group code in Rust, indicating the start and end of the function body. The double slash \//\ begins a comment that extends to the end of the line, intended for human readers and ignored by the compiler. Every Rust program must have exactly one global function named \main()\. The program starts by executing this function. Unlike C++, the \main\ function in Rust does not return a value to the system by default; it assumes successful completion unless an explicit return value or error is specified.
Typically, a program produces some output. Here is a program that prints "Hello, World!":
fn main() {
println!("Hello, World!");
}
In Rust, the println! macro is used for output. The expression
println!("Hello, World!");
writes "Hello, World!" to the console. The println! macro is part of Rust's standard library and requires no additional imports to use. The println! macro uses the format string syntax, where the string literal "Hello, World!" is surrounded by double quotes. In a string literal, the backslash character \ followed by another character denotes a special character. In this case, \n is the newline character, so the output is "Hello, World!" followed by a newline.
Essentially all executable code in Rust is placed in functions and called directly or indirectly from main(). For example:
fn square(x: f64) -> f64 {
x * x
}
fn print_square(x: f64) {
println!("the square of {} is {}", x, square(x));
}
fn main() {
print_square(1.234); // prints: the square of 1.234 is 1.522756
}
A () return type indicates that a function does not return a value.
2.4. Types, Variables, and Arithmetic
Every name and every expression in Rust has a type that determines the operations that may be performed on it. For example, the declaration
let inch: i32;
specifies that inch is of type i32; that is, inch is an integer variable.
In Rust, a declaration is a statement that introduces a new name into the program and specifies the type associated with that name. This process is fundamental to defining and using data within a Rust program. Here’s a deeper look into the key concepts involved:
Type: A type in Rust defines a set of possible values and the operations that can be performed on those values. For instance, the
i32type represents a 32-bit signed integer and supports operations such as addition, subtraction, and comparison. Types provide a way to categorize and manage data, ensuring that operations are consistent with the kind of data being handled.Object: An object refers to a piece of memory that stores a value of a specific type. In Rust, when you declare a variable, you are essentially allocating a block of memory to hold a value and associating that memory with a type. This memory holds the data that your program will work with.
Value: A value represents a set of bits stored in memory, interpreted according to its type. For example, if a variable is of type
u8, the bits stored in memory are interpreted as an unsigned 8-bit integer. The value is how the raw bits in memory are understood and used based on the type definition.Variable: A variable is essentially a named object. It is a reference to a specific piece of memory where a value of a given type is stored. By naming this object, you create a way to access and manipulate the data it holds throughout your program. For example,
let x: i32 = 5;declares a variablexthat is ani32object holding the value5.
A declaration in Rust not only introduces a name but also specifies the type of data that can be stored and manipulated. The type dictates the operations allowed, the object is the memory holding the value, the value is the interpreted set of bits, and the variable is the named reference to this object. Understanding these concepts is crucial for managing data and ensuring type safety in Rust programs.
Rust offers a variety of fundamental types. For example:
bool // Boolean, possible values are true and false
char // character, for example, 'a', 'z', and '9'
i32 // 32-bit integer, for example, 1, 42, and 1066
f64` // double-precision floating-point number, for example, 3.14 and 299793.0
Each fundamental type corresponds directly to hardware facilities and has a fixed size that determines the range of values that can be stored in it.
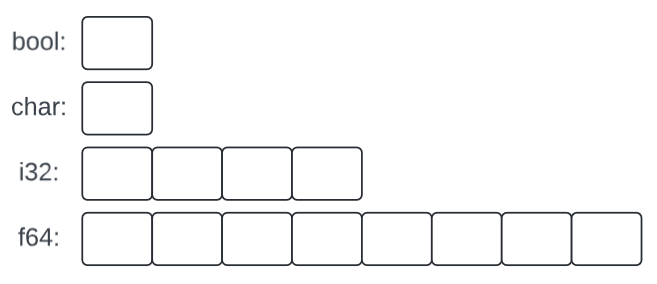
Figure 2: Fundamental types in Rust
In Rust, the char type is used to represent a single Unicode scalar value, which encompasses most of the characters you might use, including letters, digits, and symbols from various languages and scripts. By design, a char in Rust is 4 bytes (32 bits) in size. This 32-bit size is chosen to accommodate the full range of Unicode characters, ensuring that each char can represent any valid Unicode scalar value.
Other types in Rust, such as integers and floating-point numbers, also have sizes that are specified in multiples of bytes. For example, an i32, which is a 32-bit signed integer, typically occupies 4 bytes. This consistency in size helps in managing data efficiently and performing operations with predictable memory usage.
The exact size of these types can be confirmed at runtime using the std::mem::size_of function. This function returns the size, in bytes, of the type you specify. For example, std::mem::size_of:: usually returns 4, reflecting the 4-byte size of a char, and std::mem::size_of:: also typically returns 4, indicating the size of a 32-bit integer.
It's important to note that while these sizes are generally consistent, they can vary depending on the target architecture and compilation settings. Different hardware architectures might have different requirements or optimizations that affect the size of data types. Therefore, while Rust provides a reliable default size, it’s always good to be aware of potential variations when working with different platforms or compilation configurations.
In Rust, arithmetic operators can be used for appropriate combinations of types:
x + y // addition
+x // unary plus (rarely used)
x - y // subtraction
-x // unary minus
x * y // multiplication
x / y // division
x % y // remainder (modulus) for integers
Similarly, comparison operators are used to compare values:
x == y // equal
x != y // not equal
x < y // less than
x > y // greater than
x <= y // less than or equal to
x >= y // greater than or equal to
In Rust, assignments and arithmetic operations perform meaningful conversions between basic types to allow for mixed operations:
fn some_function() {
let mut d: f64 = 2.2; // initialize floating-point number
let mut i: i32 = 7; // initialize integer
d = d + i as f64; // assign sum to d, converting i to f64
println!("d after addition: {}", d);
i = (d * i as f64) as i32; // assign product to i, converting to i32
println!("i after multiplication: {}", i);
}
fn main() {
some_function();
}
Note that = is the assignment operator, and == tests equality.
Rust offers a variety of notations for expressing initialization, such as the = used above, and a form based on curly-brace-delimited initializer lists:
fn main() {
let d1: f64 = 2.3;
let d2: f64 = 2.3;
// Representing complex numbers as tuples
let z = (1.0, 0.0); // a complex number with double-precision floating-point scalars
let z2 = (d1, d2);
let z3 = (1.0, 2.0); // the = is implicit with new()
let v = vec![1, 2, 3, 4, 5, 6]; // a vector of ints
println!("z: {}+{}i", z.0, z.1);
println!("z2: {}+{}i", z2.0, z2.1);
println!("z3: {}+{}i", z3.0, z3.1);
println!("v: {:?}", v);
}
The = form is traditional and dates back to C, but if in doubt, use the general vec![] form. If nothing else, it saves you from conversions that lose information (narrowing conversions):
fn main() {
let i1: i32 = 7.2 as i32; // i1 becomes 7
// let i2: i32 = 7.2; // error: floating-point to integer conversion not allowed directly
let i3: i32 = {7.2 as i32}; // the = is not redundant, but braces are unnecessary
println!("i1: {}", i1);
// println!("i2: {}", i2); // Uncommenting this line will cause a compilation error
println!("i3: {}", i3);
}
A constant cannot be left uninitialized and a variable should only be left uninitialized in extremely rare circumstances. Don’t introduce a name until you have a suitable value for it. User-defined types (such as String, Vec, Matrix, MotorController, and OrcWarrior) can be defined to be implicitly initialized.
When defining a variable in Rust, you don't need to explicitly state its type if it can be inferred from the initializer:
fn main() {
let b = true; // a bool
let ch = 'x'; // a char
let i = 123; // an i32
let d = 1.2; // an f64
let y: f64 = 4.0; // explicitly specifying y as f64
let z = y.sqrt(); // z will be of type f64
println!("b: {}", b);
println!("ch: {}", ch);
println!("i: {}", i);
println!("d: {}", d);
println!("y: {}", y);
println!("z: {}", z);
}
We use the let syntax for initializing variables, allowing type inference to automatically determine the appropriate type without worrying about type conversion issues. Type inference is used when specifying the type explicitly isn’t necessary. This approach is typically employed unless there are specific reasons to use explicit type annotations. Such reasons might include scenarios where a variable is declared in a wide scope, making it important to clearly indicate the type for readability, or when precise control over a variable’s range or precision is required (such as choosing f64 instead of f32). Using type inference minimizes redundancy and the need to write lengthy type names, which is particularly useful in generic programming where type names can become complex and verbose.
In addition to the conventional arithmetic and logical operators, Rust offers specific operations for modifying a variable:
x += y; // x = x + y
x -= y; // x = x - y
x *= y; // scaling: x = x * y
x /= y; // scaling: x = x / y
x %= y; // x = x % y
x += 1; // increment: x = x + 1
x -= 1; // decrement: x = x - 1
These operators are concise, convenient, and very frequently used in Rust.
2.5. Constants
Rust supports immutability through two distinct mechanisms:
const: This keyword is used to declare constants that are fixed at compile time and cannot be altered. By usingconst, you are guaranteeing that the value will remain unchanged throughout the program. The Rust compiler enforces this immutability, ensuring that the value is not modified after its initial definition.static: This keyword allows for the declaration of global data that can either be mutable or immutable. When usingstatic, if you need the global data to be mutable, it must be marked withmut. However, modifying mutable static variables requires using unsafe code, as it bypasses Rust's usual safety guarantees.
These mechanisms provide different ways to manage immutability and mutability in Rust, each with its own use cases and safety considerations. For example:
const DMV: i32 = 17; // DMV is a named constant
// const fn to allow use in constant expressions
const fn square(x: i32) -> i32 {
x * x
}
const MAX1: f64 = 1.4 * square(DMV) as f64; // OK if square(17) is a constant expression
// const MAX2: f64 = 1.4 * square(var); // error: var is not a constant expression
// static MAX3: f64 = 1.4 * square(var) as f64; // error: static initializers must be constant
fn sum(v: &Vec<f64>) -> f64 {
// sum will not modify its argument
v.iter().sum()
}
fn main() {
let var: i32 = 17; // var is not a constant
let v = vec![1.2, 3.4, 4.5]; // v is not a constant
let s1 = sum(&v); // OK: evaluated at run time
// const S2: f64 = sum(&v); // error: sum(&v) not a constant expression
println!("DMV: {}", DMV);
println!("var: {}", var);
println!("MAX1: {}", MAX1);
// println!("MAX3: {}", MAX3); // MAX3 is not defined because var is not a constant
println!("s1: {}", s1);
}
To use a function in a constant expression, it must be defined with const fn. For example:
const fn square(x: i32) -> i32 {
x * x
}
A const fn in Rust must be straightforward and limited to computing a value with a single return statement. This restriction ensures that const fn can be evaluated at compile time, making it suitable for use in constant expressions. While a const fn can accept non-constant arguments, the result in such cases is not considered a constant expression. This flexibility allows a const fn to be utilized in both constant and non-constant contexts without the need to define separate functions for each scenario.
Certain situations in Rust require constant expressions due to language rules, such as defining array bounds, match arms, and specific constant declarations. Compile-time evaluation is also crucial for performance optimization, allowing calculations to be performed ahead of time rather than at runtime. Beyond performance considerations, immutability—where an object’s state remains unchanged—is a key design principle in Rust. This principle underpins Rust's approach to safety and reliability, ensuring that data integrity is maintained throughout a program's execution.
2.6. Tests and Loops
Rust provides a conventional set of statements for expressing selection and looping. For example, here is a simple function that prompts the user and returns a boolean indicating the response:
use std::io::{self, Write};
fn accept() -> bool {
print!("Do you want to proceed (y or n)? ");
io::stdout().flush().unwrap(); // ensure the question is printed immediately
let mut answer = String::new();
io::stdin().read_line(&mut answer).unwrap();
if answer.trim().eq_ignore_ascii_case("y") {
return true;
}
false
}
fn main() {
if accept() {
println!("Proceeding...");
} else {
println!("Operation cancelled.");
}
}
To improve the function by taking an 'n' (for "no") answer into account:
use std::io::{self, Write};
fn accept2() -> bool {
print!("Do you want to proceed (y or n)? ");
io::stdout().flush().unwrap(); // ensure the question is printed immediately
let mut answer = String::new();
io::stdin().read_line(&mut answer).unwrap();
match answer.trim().to_lowercase().as_str() {
"y" => true,
"n" => false,
_ => {
println!("I'll take that for a no.");
false
}
}
}
fn main() {
if accept2() {
println!("Proceeding...");
} else {
println!("Operation cancelled.");
}
}
A match statement tests a value against a set of patterns. The patterns must be distinct, and if the value tested does not match any of them, the default pattern (_) is chosen. If no default pattern is provided, no action is taken if the value doesn’t match any case pattern.
Few programs are written without loops. For example, we might want to give the user a few tries to produce acceptable input:
use std::io::{self, Write};
fn accept3() -> bool {
let mut tries = 1;
while tries <= 3 {
print!("Do you want to proceed (y or n)? ");
io::stdout().flush().unwrap(); // ensure the question is printed immediately
let mut answer = String::new();
io::stdin().read_line(&mut answer).unwrap();
match answer.trim().to_lowercase().as_str() {
"y" => return true,
"n" => return false,
_ => {
println!("Sorry, I don't understand that.");
tries += 1; // increment
}
}
}
println!("I'll take that for a no.");
false
}
fn main() {
if accept3() {
println!("Proceeding...");
} else {
println!("Operation cancelled.");
}
}
The while statement executes until its condition becomes false.
2.7. Pointers, Arrays, and Loops
An array of elements of type char can be declared like this in Rust:
let b: [char; 6]; // array of 6 characters
Similarly, a pointer can be declared like this in Rust:
let a: *const char; // pointer to a character
In declarations, [] means "array of" and *const means "pointer to". All arrays have 0 as their lower bound, so b has six elements, v[0] to v[5]. The size of an array must be a constant expression. A pointer variable can hold the address of an element of the appropriate type:
fn main() {
let b: [char; 6] = ['0', '1', '2', '3', '4', '5'];
let a: *const char = &b[3]; // a points to b’s fourth element (index 3)
// Dereference a to get the object it points to
let x: char = unsafe { *a };
println!("The character at index 3 is: {}", x);
}
In Rust, dereferencing a raw pointer requires an unsafe block because raw pointers bypass the language's usual safety guarantees. Unlike references, raw pointers do not enforce borrowing rules or guarantee that the memory they point to is valid, which could lead to undefined behavior if misused. By requiring an unsafe block, Rust ensures that developers explicitly acknowledge and take responsibility for the potential risks involved in manipulating raw pointers, such as accessing uninitialized memory or causing data races, thereby reinforcing the language's commitment to safety and preventing inadvertent unsafe operations.
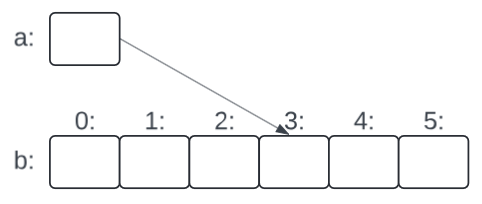
Figure 3: Unsafe dereferencing of a raw pointer in Rust.
Consider copying ten elements from one array to another in Rust:
fn copy_fct() {
let v1 = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9];
let mut v2 = [0; 10]; // to become a copy of v1
for i in 0..10 { // copy elements
v2[i] = v1[i];
}
// Printing to verify the result
println!("v1: {:?}", v1);
println!("v2: {:?}", v2);
}
fn main() {
copy_fct();
}
This for statement can be read as "set i to zero; while i is less than 10, copy the ith element and increment i." When applied to an integer variable, the increment operator, += 1, simply adds 1.
Rust also offers a simpler for loop for iterating over a sequence in the easiest way:
fn print_arrays() {
let v = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9];
// Iterating over the elements of v
for x in v.iter() { // for each x in v
println!("{}", x);
}
// Iterating over a slice of values
for x in &[10, 21, 32, 43, 54, 65] {
println!("{}", x);
}
}
fn main() {
print_arrays();
}
The first for loop can be read as "for every element in v, from the first to the last, place a reference in x and print it." Note that we don't have to specify an array size when we initialize it with a list. The for loop can be used for any sequence of elements.
If we didn’t want to copy the values from v into the variable x, but rather just have x refer to an element, we could write:
fn increment() {
let mut v = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9];
for x in &mut v {
*x += 1;
}
// Printing the modified array to verify the result
for x in &v {
println!("{}", x);
}
}
fn main() {
increment();
}
In a declaration, the prefix & means "reference to." A reference is similar to a pointer, except that you don’t need to use a prefix to access the value referred to by the reference. Also, a reference cannot be made to refer to a different object after its initialization. When used in declarations, operators (such as &, , and []) are called declarator operators:
let a: [T; n]; // [T; n]: array of n Ts
let p: *const T; // *const T: pointer to T
let r: &T; // &T: reference to T
fn f(a: A) -> T; // fn(A) -> T: function taking an argument of type A and returning a result of type T
We try to ensure that a pointer always points to an object, so that dereferencing it is valid. When we don’t have an object to point to or if we need to represent the notion of "no object available" (e.g., for an end of a list), we give the pointer the value None (the equivalent of a null pointer in Rust). There is only one None shared by all pointer types:
let pd: Option<*const f64> = None;
let lst: Option<*const Link<Record>> = None; // pointer to a Link to a Record
// let x: i32 = None; // error: None is a pointer, not an integer
It is often wise to check that a pointer argument that is supposed to point to something actually points to something:
use std::os::raw::c_char;
fn count_x(p: *const c_char, x: c_char) -> i32 {
// Count the number of occurrences of x in p[]
// p is assumed to point to a null-terminated array of c_char (or to nothing)
if p.is_null() {
return 0;
}
let mut count = 0;
unsafe {
let mut ptr = p;
while *ptr != 0 {
if *ptr == x {
count += 1;
}
ptr = ptr.add(1); // move pointer to the next element
}
}
count
}
fn main() {
// Example usage
let c_str = std::ffi::CString::new("hello world").unwrap();
let c_ptr = c_str.as_ptr();
let count = count_x(c_ptr, 'o' as c_char);
println!("The character 'o' appears {} times.", count);
}
Notice that we can advance a pointer to the next element in an array using p.add(1). Additionally, in a for loop, the initializer can be omitted if it's not needed. The count_x() function is defined with the assumption that the *const char is a C-style string, which means the pointer refers to a null-terminated array of char. In older codebases, 0 or NULL was commonly used instead of None. However, using None helps avoid confusion between integers like 0 or NULL and pointers represented by None, making the code clearer and more consistent.
2.8. User-Defined Types
In Rust, built-in types are fundamental constructs such as integers, floating-point numbers, characters, and booleans. These types are designed to be close to the hardware, which means they are efficient and directly reflect the capabilities of the underlying computer architecture. For instance, an i32 is a 32-bit signed integer, and f64 is a 64-bit floating-point number. They provide essential operations and are optimized for performance but are limited in their ability to represent more complex data structures or higher-level abstractions.
To address these limitations, Rust provides mechanisms for creating user-defined types. These types are constructed using the built-in types and allow for more sophisticated data modeling. User-defined types in Rust primarily include structs and enums.
Structs allow developers to bundle multiple related pieces of data into a single entity. For example, you might use a struct to represent a Point in a 2D space, encapsulating both x and y coordinates. This grouping of data into a coherent unit makes it easier to manage and work with complex data structures in a more intuitive way.
Enums, on the other hand, allow you to define a type that can be one of several possible variants. This is useful for representing a value that could be different types of things. For example, an enum might represent various shapes, like circles and rectangles, where each variant holds different data relevant to that shape. This allows for a clear and type-safe way to handle different cases in your code.
Rust’s abstraction mechanisms enable the creation of high-level constructs that can model complex systems or data structures, extending the capabilities of built-in types. By defining these user-defined types, programmers can encapsulate data and functionality in a manner that fits the specific needs of their application, leading to more readable, maintainable, and expressive code.
These abstractions are crucial for developing robust and sophisticated software, as they allow programmers to build and use types that go beyond the limitations of the basic built-in types. Rust's standard library exemplifies these capabilities with a wide range of user-defined types and abstractions that demonstrate how the language's features can be used to create powerful and flexible software solutions.
2.9. Structures
The first step in building a new type is often to organize the elements it needs into a data structure, a struct:
struct Vector {
sz: usize, // number of elements
elem: *mut f64, // pointer to elements
}
This first version of Vector consists of a usize and a *mut f64.
A variable of type Vector can be defined like this in Rust:
let v = Vector {
sz: 0,
elem: std::ptr::null_mut(),
};
However, by itself, that is not of much use because v’s elem pointer doesn’t point to anything. To be useful, we must give v some elements to point to. For example, we can construct a Vector like this:
fn vector_init(v: &mut Vector, s: usize) {
v.elem = vec![0.0; s].into_boxed_slice().as_mut_ptr(); // allocate an array of s doubles
v.sz = s;
}
In this example, v’s elem member gets a pointer produced by allocating a Vec and converting it to a raw pointer, and v’s sz member gets the number of elements. The &mut Vector indicates that we pass v by mutable reference so that vector_init() can modify the vector passed to it.
The vec! macro allocates memory from an area called the heap (also known as dynamic memory).
There is a long way to go before our Vector is as elegant and flexible as the standard library's Vec. In particular, a user of Vector has to know every detail of Vector's representation. The rest of this section and the next gradually improve Vector as an example of language features and techniques.
We use Vec and other standard library components as examples:
to illustrate language features and design techniques, and
to help you learn and use the standard library components.
The emphasis on using standard library components, like Vec and String, rather than creating your own implementations, is important because these components have been thoroughly tested and optimized by the Rust community. They come with guarantees of performance and safety that custom implementations might not. Moreover, reinventing these components can lead to unnecessary complexity and potential errors, whereas using the standard library versions ensures you benefit from decades of collective expertise and robust design.
We use . (dot) to access struct members through a name (and through a reference) and * to dereference a pointer to access struct members. For example:
fn f(v: Vector, rv: &Vector, pv: *const Vector) {
let i1 = v.sz; // access through name
let i2 = rv.sz; // access through reference
let i3 = unsafe { (*pv).sz }; // access through pointer
}
In Rust, accessing struct members through a name or reference is straightforward with the . operator. When accessing through a pointer, we use the * operator to dereference the pointer and then access the member. The unsafe block is necessary because dereferencing raw pointers is considered unsafe in Rust.
2.10. Structs in Rust
Separating data from the operations performed on it has its benefits, such as offering flexibility in how the data can be utilized. However, for a user-defined type to fully embody the characteristics of a "real type," a more integrated approach is necessary, where the data’s representation is closely tied to its operations. This integration helps in maintaining data integrity, ensuring consistent usage, and allowing future enhancements to the representation without exposing internal details to users.
To achieve this, Rust uses the concept of a struct with associated functions. A struct in Rust can include various fields, and you can define methods to manipulate these fields. The public methods of a struct define its interface, which users interact with, while the private fields remain hidden from direct access. This design ensures that all interactions with the struct are mediated through its defined methods, maintaining control over how the data is accessed and modified.For example:
struct Vector {
elem: Box<[f64]>, // pointer to the elements
sz: usize, // the number of elements
}
impl Vector {
// Constructor to create a new Vector
fn new(s: usize) -> Vector {
Vector {
elem: vec![0.0; s].into_boxed_slice(), // Allocate elements on the heap
sz: s,
}
}
// Method to get the element at a given index
fn get(&self, i: usize) -> f64 {
self.elem[i]
}
// Method to set the element at a given index
fn set(&mut self, i: usize, value: f64) {
self.elem[i] = value;
}
// Method to get the size of the Vector
fn size(&self) -> usize {
self.sz
}
}
fn main() {
// Create a new Vector of size 6
let mut vec = Vector::new(6);
// Set values in the Vector
for i in 0..vec.size() {
vec.set(i, i as f64);
}
// Get and print values from the Vector
for i in 0..vec.size() {
println!("vec[{}] = {}", i, vec.get(i));
}
}
Given that, we can define a variable of our new type Vector:
let mut v = Vector::new(6); // a Vector with 6 elements
In this example, the Vector struct has private fields (elem and sz) and public methods (new, get, set, and size) that provide controlled access to the data. This encapsulation ensures that the data can only be accessed and modified in intended ways, allowing for future improvements to the implementation without affecting the interface.
We can illustrate a Vector object graphically:
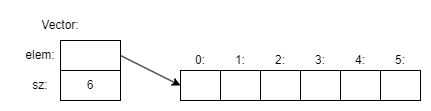
Figure 4: Vector implementation in Rust.
Essentially, the Vector object acts as a "handle" that contains a pointer to the elements (elem) and the number of elements (sz). The number of elements (6 in this example) can differ between Vector objects and can change over time for a given Vector object. Despite this variability, the Vector object itself maintains a consistent size. This approach, where a fixed-size handle manages a variable amount of data stored elsewhere, is a fundamental technique in Rust for managing dynamic information. Understanding how to design and use such objects is a key aspect of Rust programming.
In Rust, the representation of a Vector (with fields elem and sz) is only accessible through the interface provided by the public methods: new(), get(), and size(). The read_and_sum() example can be simplified as follows:
struct Vector {
elem: Box<[f64]>, // pointer to the elements
sz: usize, // the number of elements
}
impl Vector {
// Constructor to create a new Vector
fn new(s: usize) -> Vector {
Vector {
elem: vec![0.0; s].into_boxed_slice(), // Allocate elements on the heap
sz: s,
}
}
// Method to get the element at a given index
fn get(&self, i: usize) -> f64 {
self.elem[i]
}
// Method to set the element at a given index
fn set(&mut self, i: usize, value: f64) {
self.elem[i] = value;
}
// Method to get the size of the Vector
fn size(&self) -> usize {
self.sz
}
}
fn read_and_sum(s: usize) -> f64 {
let mut v = Vector::new(s); // create a vector with s elements
for i in 0..v.size() {
let mut input = String::new();
std::io::stdin().read_line(&mut input).expect("Failed to read line");
v.set(i, input.trim().parse().expect("Please enter a number"));
}
let mut sum = 0.0;
for i in 0..v.size() {
sum += v.get(i);
}
sum
}
fn main() {
let s = 5; // Specify the number of elements to read
println!("Enter {} numbers:", s);
let sum = read_and_sum(s);
println!("The sum of the entered numbers is: {}", sum);
}
A function with the same name as its struct, such as new(), acts as a constructor and is used to create instances of the struct. Thus, Vector::new() replaces the need for a manual initialization function. Constructors ensure that instances of the struct are properly initialized, solving the issue of uninitialized variables.
The Vector::new(usize) method defines how to create Vector objects. It requires an integer input, which specifies the number of elements the Vector should have. This integer is used to determine the size of the Vector. The constructor initializes the Vector fields using a member initializer list:
use std::io::{self, Write}; // Import necessary modules
// Define the Vector struct
struct Vector {
elem: Box<[f64]>, // Pointer to the elements
sz: usize, // Number of elements
}
impl Vector {
// Constructor to create a new Vector
fn new(s: usize) -> Vector {
Vector {
elem: vec![0.0; s].into_boxed_slice(), // Allocate elements on the heap
sz: s,
}
}
// Method to get the element at a given index
fn get(&self, i: usize) -> f64 {
self.elem[i]
}
// Method to set the element at a given index
fn set(&mut self, i: usize, value: f64) {
self.elem[i] = value;
}
// Method to get the size of the Vector
fn size(&self) -> usize {
self.sz
}
}
// Function to read values into the Vector and compute the sum
fn read_and_sum(s: usize) -> f64 {
let mut v = Vector::new(s); // Create a Vector with s elements
for i in 0..v.size() {
print!("Enter number {}: ", i + 1);
io::stdout().flush().unwrap(); // Ensure the prompt is displayed immediately
let mut input = String::new();
io::stdin().read_line(&mut input).expect("Failed to read line");
v.set(i, input.trim().parse().expect("Please enter a valid number"));
}
let mut sum = 0.0;
for i in 0..v.size() {
sum += v.get(i);
}
sum
}
// Main function to demonstrate the usage
fn main() {
let s = 5; // Specify the number of elements to read
println!("You will enter {} numbers.", s);
let sum = read_and_sum(s);
println!("The sum of the entered numbers is: {}", sum);
}
Here, elem is first initialized with a pointer to an array of s elements of type f64, allocated on the heap. After that, sz is set to s.
Element access is provided by a method called \get\, which returns a reference to the specified element (\&f64\). The \size\ method allows users to retrieve the number of elements in the vector.
2.11. Enumerations in Rust
Besides structs, Rust offers a simple user-defined type called an enum, which allows us to list possible values:
// Define the Color enum
enum Color {
Red,
Blue,
Green,
}
// Define the TrafficLight enum
enum TrafficLight {
Green,
Yellow,
Red,
}
fn main() {
// Create instances of the enums
let col = Color::Red;
let light = TrafficLight::Red;
// Match and print the values to demonstrate usage
match col {
Color::Red => println!("Color is Red"),
Color::Blue => println!("Color is Blue"),
Color::Green => println!("Color is Green"),
}
match light {
TrafficLight::Green => println!("Traffic light is Green"),
TrafficLight::Yellow => println!("Traffic light is Yellow"),
TrafficLight::Red => println!("Traffic light is Red"),
}
}
In Rust, the variants (e.g., Red) are scoped within their respective enums, enabling them to be used in multiple enums without conflict. For example, Color::Red is separate from TrafficLight::Red.
Enums in Rust are a powerful feature for defining a type that can be one of several different variants, each with its own specific value or structure. They are particularly useful for representing small, fixed sets of potential values, such as states in a state machine, options in a configuration, or different types of messages in a communication protocol.
One of the primary benefits of using enums is the clarity they bring to the code. Instead of relying on simple integers or other primitive types, enums use symbolic and descriptive names for each variant. This not only makes the code more readable but also helps reduce errors. For instance, instead of using numeric constants like 0, 1, and 2 to represent different states, you can use descriptive names like Pending, Processing, and Completed. This makes the code self-documenting and easier to understand, minimizing the likelihood of mistakes due to misinterpretation of what each value represents.
Rust enums are strongly typed, meaning that each variant is associated with a specific enum type. This strong typing prevents accidental misuse of constants and ensures that values from different enums cannot be mixed up. For example, if you have an enum Status with variants Active, Inactive, and Pending, you cannot accidentally assign a variant from another enum, like Error, to a variable of type Status. This strong type safety helps catch errors at compile time, making your code more robust and less prone to bugs.
In addition to improving type safety and code clarity, Rust enums support pattern matching, which allows you to handle different variants in a concise and expressive manner. This feature, combined with the strong typing, makes enums a versatile and essential tool for writing clean, maintainable Rust code.
By default, an enum in Rust supports basic operations like assignment, initialization, and comparisons (e.g., == and <). Since an enum is a user-defined type, we can also add custom methods to it:
// Define the TrafficLight enum
enum TrafficLight {
Green,
Yellow,
Red,
}
// Implement the TrafficLight enum with a custom method
impl TrafficLight {
fn next(&self) -> TrafficLight {
match self {
TrafficLight::Green => TrafficLight::Yellow,
TrafficLight::Yellow => TrafficLight::Red,
TrafficLight::Red => TrafficLight::Green,
}
}
}
fn main() {
let light = TrafficLight::Red;
let next = light.next(); // next becomes TrafficLight::Green
// Print the current and next traffic light states
match light {
TrafficLight::Green => println!("Current light is Green"),
TrafficLight::Yellow => println!("Current light is Yellow"),
TrafficLight::Red => println!("Current light is Red"),
}
match next {
TrafficLight::Green => println!("Next light is Green"),
TrafficLight::Yellow => println!("Next light is Yellow"),
TrafficLight::Red => println!("Next light is Red"),
}
}
Rust’s enum system differs significantly from that of C++ in terms of type safety and scope. In C++, plain enums are essentially named integer constants and do not enforce strict typing. This means that the values of a plain enum are treated as simple integers, which can lead to potential issues such as inadvertently mixing values from different enums or misusing these values inappropriately. The lack of strict type enforcement in C++ means that values from one enum can be mistakenly assigned to a variable of another enum type or used in unintended ways, potentially leading to errors or undefined behavior.
In contrast, Rust’s enums are strongly typed and scoped. Each enum in Rust is a distinct type with its own set of well-defined variants. This strong typing ensures that each enum’s variants are strictly tied to the enum type itself, preventing any accidental mixing with variants from other enums or direct use of raw integer values. Rust’s type system enforces that you use only the defined variants of the enum, which adds a layer of safety and clarity to the code. This strict enforcement helps to avoid common mistakes, ensures more predictable behavior, and improves the overall robustness of the code.
By maintaining this strong typing and scoping, Rust provides a more controlled and error-resistant approach to working with enums, in contrast to the more permissive and less type-safe handling found in C++.
2.12. Modularity
In Rust, a program is typically made up of various components like functions, user-defined types, trait implementations, and generics. Each of these components plays a specific role and contributes to the overall functionality of the program. Effectively managing these components requires a clear understanding of how they interact with one another and how they are organized within the code.
One of the most important aspects of managing these components is distinguishing between the interface and the implementation of each part. The interface of a component is essentially its public contract—it defines what a function or type is and what it does, including its public methods and how it should be used by other parts of the program. This is done through declarations, which include function signatures, type definitions, and trait declarations. These declarations provide all the necessary information needed to interact with the component without revealing the internal workings or details of how it is implemented.
On the other hand, the implementation of a component encompasses the actual code that performs the operations and provides the functionality. It includes the specific logic of functions, the internal structure of types, and the actual code for trait methods. The implementation details are kept separate from the interface to encapsulate how the functionality is achieved, which allows for modifications and improvements to the internal workings without affecting the parts of the program that rely on the component's interface.
This separation of interface and implementation not only promotes modularity and reusability but also enhances maintainability. By adhering to this principle, you can ensure that components are used correctly according to their defined contracts, while their internal details remain hidden and protected. This approach helps in managing complexity and ensures that changes to one part of the program do not inadvertently break other parts, thereby fostering a more robust and organized codebase. For example:
// Import the necessary module for the sqrt function
use std::f64;
// Define the sqrt function
fn sqrt(x: f64) -> f64 {
x.sqrt()
}
// Define the Vector struct
struct Vector {
elem: Box<[f64]>, // elem points to an array of f64s
sz: usize,
}
impl Vector {
// Constructor to create a new Vector
fn new(s: usize) -> Vector {
Vector {
elem: vec![0.0; s].into_boxed_slice(), // Allocate elements on the heap
sz: s,
}
}
// Method to get the element at a given index
fn get(&self, i: usize) -> f64 {
self.elem[i]
}
// Method to get the size of the Vector
fn size(&self) -> usize {
self.sz
}
}
fn main() {
// Create a new Vector of size 5
let vec = Vector::new(5);
// Print the size of the Vector
println!("Size of the vector: {}", vec.size());
// Example usage of the sqrt function
let value = 16.0;
println!("The square root of {} is {}", value, sqrt(value));
// Get and print elements from the Vector
for i in 0..vec.size() {
println!("vec[{}] = {}", i, vec.get(i));
}
}
The important point is that the bodies of the functions, or their definitions, are separate from their declarations. In this example, the implementation of sqrt() would be defined elsewhere, but let's focus on the Vector struct for now. We define all the methods for Vector like this:
impl Vector {
fn new(s: usize) -> Vector {
Vector {
elem: vec![0.0; s].into_boxed_slice(),
sz: s,
}
}
fn get(&self, i: usize) -> f64 {
self.elem[i]
}
fn size(&self) -> usize {
self.sz
}
}
We must define the methods for Vector, just as we define the sqrt() function, even though sqrt() might be provided by a standard library. The functions in the standard library are essentially "other code we use," created using the same language features that we use.
Here’s the complete code with the Vector struct and its methods:
// Import the necessary module for the sqrt function
use std::f64;
// Define the sqrt function
fn sqrt(x: f64) -> f64 {
x.sqrt()
}
// Define the Vector struct
struct Vector {
elem: Box<[f64]>, // elem points to an array of f64s
sz: usize,
}
impl Vector {
// Constructor to create a new Vector
fn new(s: usize) -> Vector {
Vector {
elem: vec![0.0; s].into_boxed_slice(), // Allocate elements on the heap
sz: s,
}
}
// Method to get the element at a given index
fn get(&self, i: usize) -> f64 {
self.elem[i]
}
// Method to get the size of the Vector
fn size(&self) -> usize {
self.sz
}
}
fn main() {
// Create a new Vector of size 5
let vec = Vector::new(5);
// Print the size of the Vector
println!("Size of the vector: {}", vec.size());
// Example usage of the sqrt function
let value = 16.0;
println!("The square root of {} is {}", value, sqrt(value));
// Get and print elements from the Vector
for i in 0..vec.size() {
println!("vec[{}] = {}", i, vec.get(i));
}
}
2.13. Separate Compilation
Rust’s support for separate compilation is a key feature that enhances modularity, organization, and efficiency in programming. This approach allows a Rust program to be divided into multiple source files, each handling different parts of the code. By compiling these parts independently, Rust promotes a clear separation of concerns and improves overall code management.
In practice, separate compilation means that the declarations of types and functions are made visible to the rest of the program, while the detailed definitions of these types and functions are kept in separate source files. This means that when you use a function or type from another part of your code or from an external library, you only need to know its public interface—the declarations that specify what the function or type does and how to interact with it. The actual implementation, which includes the detailed code and logic, resides in different source files.
This modular approach has several advantages. It helps in organizing the program into semi-independent units, which makes it easier to manage and understand. Each module or source file can focus on a specific aspect of the program, reducing complexity and making the codebase more maintainable. Additionally, by compiling modules separately, Rust reduces compilation times, as changes in one part of the code do not require recompiling the entire program. Instead, only the modified parts and their dependencies are recompiled.
Libraries in Rust follow the same principle of separate compilation. Libraries are collections of functions, types, and other code segments that are compiled independently from the main program. When you use a library, you interact with it through its public interface, which is defined in its declarations. The internal details of the library are encapsulated and managed separately, ensuring a clean and efficient integration.
Overall, separate compilation in Rust fosters a well-organized code structure, enhances modularity, and improves build efficiency, while also enforcing a clear separation between different parts of the program. This not only helps in minimizing errors but also makes large and complex codebases more manageable and scalable.
Typically, we place the declarations that define a module's interface in a file named to reflect its purpose. For example:
// Vector.rs
pub struct Vector {
elem: Box<[f64]>,
sz: usize,
}
impl Vector {
pub fn new(s: usize) -> Vector {
Vector {
elem: vec![0.0; s].into_boxed_slice(),
sz: s,
}
}
pub fn get(&self, i: usize) -> f64 {
self.elem[i]
}
pub fn size(&self) -> usize {
self.sz
}
}
This declaration would go in a file named vector.rs, and users would import this module to use its interface. For example:
// Main.rs
mod Vector;
use Vector::Vector;
use std::f64::consts::SQRT_2; // example of using a standard library constant
fn sqrt_sum(v: &Vector) -> f64 {
let mut sum = 0.0;
for i in 0..v.size() {
sum += v.get(i).sqrt(); // sum of square roots
}
sum
}
In this example, Vector.rs contains the definition of the Vector struct and its methods, while Main.rs imports this module to utilize Vector. The use keyword brings items from the module and the standard library into scope, making them available in the code.
To ensure consistency, the Vector.rs file that provides the implementation of Vector also includes the module declaration for its interface:
// Vector.rs
pub struct Vector {
elem: Box<[f64]>,
sz: usize,
}
impl Vector {
pub fn new(s: usize) -> Vector {
Vector {
elem: vec![0.0; s].into_boxed_slice(),
sz: s,
}
}
pub fn get(&self, i: usize) -> f64 {
self.elem[i]
}
pub fn size(&self) -> usize {
self.sz
}
}
The Main.rs file will import this module to use the Vector interface:
// Main.rs
mod Vector;
use Vector::Vector;
fn main() {
let v = Vector::new(10);
println!("Size: {}", v.size());
for i in 0..v.size() {
println!("Element {}: {}", i, v.get(i));
}
}
fn sqrt_sum(v: &Vector) -> f64 {
let mut sum = 0.0;
for i in 0..v.size() {
sum += v.get(i).sqrt(); // sum of square roots
}
sum
}
In this setup, Main.rs and Vector.rs share the Vector interface information defined in Vector.rs, but the two files are otherwise independent and can be compiled separately. This modular approach allows for separate compilation and maintains the independence of program components.
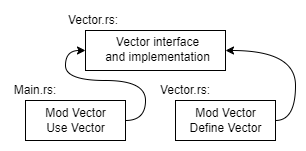
Figure 5: Modular design of Vector implementation.
Separate compilation is a concept that extends beyond the specifics of any one programming language. Instead, it relates to how a language's features and implementation can be used to manage and compile code in a modular and efficient way. While the underlying principle is not unique to Rust or any other language, Rust provides robust mechanisms to support and enhance this practice.
The practical importance of separate compilation lies in its ability to improve code organization, maintainability, and build efficiency. To fully leverage separate compilation, it's essential to approach it through a combination of modularity and organization.
Modularity is a key aspect here. It involves breaking down a program into smaller, manageable units or components that can be developed and tested independently. In Rust, this is achieved through constructs such as modules and crates. Modules are used to logically group related functions, types, and constants within a single file or across multiple files, while crates serve as the primary unit of code distribution and compilation, encapsulating related modules and other resources.
Logical Representation of modularity is accomplished through the language’s features. In Rust, you define modules and crates to represent different parts of your program. Modules allow you to organize code within a file or across files, while crates represent a package of code that can be compiled and used independently. This logical separation helps you manage code more effectively by keeping related functionalities together and maintaining clear boundaries between different parts of the codebase.
2.14. Modules
In addition to functions, structs, and enums, Rust offers modules as a way to group related declarations and prevent name clashes. For example, you might want to experiment with your own complex number type:
mod custom {
pub struct Complex {
// fields and methods for Complex
}
pub fn sqrt(c: Complex) -> Complex {
// implementation for sqrt
}
pub fn main() {
let z = Complex { /* initialization */ };
let z2 = sqrt(z);
println!("{{{}, {}}}", z2.real(), z2.imag());
// ...
}
}
fn main() {
custom::main();
}
By placing the code in the custom module, it ensures that the names do not conflict with the standard library names in the std module. This precaution is wise because the standard library provides support for complex arithmetic.
The easiest way to access a name from another module is by prefixing it with the module name (e.g., std::io::stdout and custom::main). The main function is defined in the global scope, meaning it isn't part of any specific module, struct, or function. To bring names from the standard library into scope, we use the use statement:
use std::io;
Modules are mainly used to organize larger components of a program, such as libraries. They make it easier to build a program from independently developed parts.
2.15. Error Handling
Error handling in Rust is a multifaceted subject that extends beyond mere language syntax to include broader programming strategies and tools. Rust approaches error handling through a combination of a strong type system and powerful abstractions that facilitate the development of robust and reliable applications.
Rust’s type system plays a crucial role in this process. Instead of relying solely on primitive types like char, i32, and f64, and basic control structures such as if, while, and for, Rust encourages the use of more sophisticated types and constructs. These include String for dynamic text, HashMap for associative arrays, and Regex for regular expressions. By employing these higher-level abstractions, developers can write more expressive and error-resistant code. The use of specialized types and algorithms, such as sort, find, and draw_all, not only simplifies development but also allows the Rust compiler to perform more rigorous checks, catching potential errors early in the development process.
Rust's design philosophy emphasizes creating clean and efficient abstractions. This includes defining custom user types and implementing associated algorithms that fit specific needs. This modular approach means that code can be organized into components with clear interfaces, reducing the likelihood of errors and improving maintainability. As applications grow and make use of various libraries, the point at which errors occur may be different from where they are handled. This separation can complicate error management but also underscores the need for consistent error handling practices.
To effectively handle errors in a Rust application, developers must establish robust error handling standards. These standards should account for the potential complexity introduced by extensive library use and modular design. By integrating Rust’s type system and leveraging its abstraction mechanisms, developers can create applications that handle errors gracefully and maintain high reliability.
2.16. Exceptions
Consider the Vector example. How should out-of-range element access be handled? The Vector implementer doesn't know what the user wants to happen in such situations, and the user can't always prevent out-of-range accesses. The solution is for the Vector implementer to catch these errors and notify the user. In Rust, this can be managed with the Result type to indicate potential errors. For instance, the Vector implementation can return a Result to show either success or an error:
impl Vector {
pub fn get(&self, i: usize) -> Result<f64, String> {
if i >= self.sz {
Err(format!("Index {} out of range for Vector", i))
} else {
Ok(self.elem[i])
}
}
}
The get method checks for out-of-range access and returns an Err variant if the index is invalid. The user can then handle this error accordingly:
fn main() {
let v = Vector::new(10);
match v.get(10) {
Ok(value) => println!("Value: {}", value),
Err(e) => println!("Error: {}", e),
}
}
In this example, the attempt to access v.get(10) will fail, and an error message will be displayed. Using the Result type for error handling in Rust makes error management more systematic and readable.
2.17. Invariants
Using the Result type to handle out-of-range access in Rust demonstrates how functions can validate their arguments and refuse execution if fundamental conditions, or preconditions, are not met. For example, if we were to formally define the subscript operator for a Vector, it would include a requirement such as "the index must be within the range \[0())". This is precisely what our get() method verifies. When defining functions, it's crucial to identify and validate their preconditions to ensure they are met. This practice enhances reliability and helps prevent unexpected errors.
The get() method works on Vector objects, and its operations are only meaningful if the Vector's fields have valid values. For instance, we mentioned that elem points to an array of sz doubles, but this was only noted in a comment. Such a statement, indicating what must always be true for a class, is known as a class invariant, or simply an invariant. The constructor's responsibility is to establish this invariant (so member functions can depend on it), and the member functions must ensure the invariant holds when they finish execution. Unfortunately, our Vector constructor did not fully achieve this. It correctly initialized the Vector fields but didn't validate that the arguments provided were reasonable. For example:
let v = Vector::new(-27);
This would likely cause serious problems. To address this in Rust, we can modify the constructor as follows:
impl Vector {
pub fn new(s: isize) -> Result<Vector, String> {
if s < 0 {
Err(String::from("Size must be non-negative"))
} else {
Ok(Vector {
elem: vec![0.0; s as usize].into_boxed_slice(),
sz: s as usize,
})
}
}
}
This ensures that the constructor validates the arguments, maintaining the invariant that sz must be non-negative.
Here is a more appropriate definition:
impl Vector {
pub fn new(s: isize) -> Result<Vector, String> {
if s < 0 {
return Err(String::from("Size must be non-negative"));
}
Ok(Vector {
elem: vec![0.0; s as usize].into_boxed_slice(),
sz: s as usize,
})
}
}
The standard library error type is used to report a non-positive number of elements, as similar operations use this error type to signal such issues. If memory allocation fails, Rust will return an error instead of throwing an exception. The following example shows how to handle these cases:
fn test() {
match Vector::new(-27) {
Ok(v) => {
// use the vector
},
Err(e) => {
if e == "Size must be non-negative" {
// handle negative size
} else {
// handle other errors
}
}
}
}
In Rust, custom error types are instrumental for conveying detailed information about errors from the point of detection to the point of handling. By defining custom error types, you can encapsulate specific error conditions and their context, making error handling more informative and manageable.
Rust does not use traditional exception handling mechanisms. Instead, it relies on the Result and Option types to handle errors. When a function encounters an error, it typically returns a Result type that either contains a success value or an error value. When the function cannot complete its task due to an error, it handles the situation by performing minimal local cleanup if necessary and then propagating the error up the call stack. This approach allows higher-level code to manage the error appropriately.
The concept of invariants and preconditions plays a significant role in designing robust software. Invariants are conditions that must always hold true for an object to remain valid throughout its lifecycle. They help maintain the consistency and correctness of an object's state. On the other hand, preconditions are conditions that must be met before a function can execute correctly. They ensure that the function operates under valid assumptions, preventing it from executing with invalid inputs. By clearly defining and enforcing these conditions, you improve the reliability and robustness of your code, making it easier to debug and test.
2.18. Static Assertions
In Rust, error handling can be effectively managed through the type system and compile-time checks, offering a more robust alternative to runtime exceptions. While exceptions traditionally report errors that occur during program execution, Rust aims to catch as many errors as possible at compile time, reducing the risk of encountering unexpected issues during runtime.
Rust's type system is designed to enforce strict rules about how values are used and manipulated, catching many common errors before the code is even executed. By leveraging Rust's type system, developers can define precise interfaces for user-defined types, specifying the exact conditions under which these types can be used. This approach helps prevent misuse and ensures that errors are caught early in the development process.
Furthermore, Rust's compiler performs extensive checks to enforce these rules. For instance, Rust's ownership and borrowing system guarantees memory safety and prevents data races at compile time. If the compiler detects a violation of these rules, it reports the issue as a compiler error, prompting the developer to fix the problem before the code can be compiled and run.
By focusing on compile-time error detection, Rust provides a more reliable and predictable development experience. Developers can catch and resolve issues early, reducing the likelihood of runtime errors and improving the overall quality of their code. This emphasis on compile-time checks distinguishes Rust from many other languages, making it particularly well-suited for systems programming and other domains where reliability and performance are critical. For instance:
const_assert!(std::mem::size_of::<i32>() >= 4, "integers are too small"); // check integer size
This will produce the error message "integers are too small" if std::mem::size_of:: is false, indicating that an i32 on this system is less than 4 bytes. These expectation statements are called assertions.
The const_assert feature in Rust can be applied to any situation that can be described using constant expressions. For example:
const C: f64 = 299_792.458; // speed of light in km/s
fn f(speed: f64) {
const LOCAL_MAX: f64 = 160.0 / (60.0 * 60.0); // converting 160 km/h to km/s
const_assert!(speed < C, "can't go that fast"); // error: speed must be a constant
const_assert!(LOCAL_MAX < C, "can't go that fast"); // OK
// ...
}
In general, const_assert!(A, S) generates S as a compiler error message if A evaluates to false. The most valuable application of const_assert is in making assertions about types used as parameters in generic programming.
2.19. Advices
As you embark on learning Rust, it is crucial to adopt a patient and steady approach. Initially, Rust may appear complex due to its unique features and strict rules, but persistence will enable you to gradually master its intricacies. At the outset, focus on understanding Rust’s foundational concepts such as ownership, borrowing, and lifetimes. These principles are central to Rust's design and are essential for writing safe and efficient code. Emphasize gaining a deep comprehension of these concepts rather than merely memorizing syntax. They are the bedrock of Rust’s memory safety and concurrency guarantees, and mastering them will greatly enhance your ability to write reliable code.
Beyond these foundational concepts, it is beneficial to explore Rust’s advanced features. The language’s robust type system allows for precise and expressive programming, facilitating the creation of complex and scalable applications. Pay attention to how Rust's type system enables you to write code that is both safe and performant by catching errors at compile time. Additionally, Rust’s concurrency model offers powerful tools for managing parallel execution while preventing common issues such as data races and deadlocks. Understanding how to effectively use Rust’s concurrency features will empower you to develop high-performance applications that can efficiently utilize modern hardware.
Establishing a strong grasp of these core principles will not only help you navigate Rust’s complexities but also enable you to leverage its powerful capabilities fully. By focusing on foundational concepts and exploring advanced features, you will position yourself to excel in Rust development and harness its potential for building robust and scalable software.
2.20. Further Learning with GenAI
Assign yourself the following tasks: Input each prompt into both ChatGPT and Gemini, and analyze the responses to deepen your understanding of Rust.
As a senior Rust programmer, elaborate on the concept of separate compilation using the
rustccompiler. Given two source files,main.rsandlib.rs, provide a comprehensive guide on manually compiling these files with the--crate-type=liband--emit=objcompiler options. Discuss the use cases and advantages of each technique, including their impact on build times, code organization, and binary sizes.Continue with
main.rsandlib.rsto offer a detailed guide on achieving separate compilation using Cargo, Rust's package manager and build system. Explain the process of setting up a project, managing dependencies, and efficiently building the project. Highlight the benefits of using Cargo over manual compilation, such as dependency management, build automation, and workspace support.Write sample Rust code for a "Hello, World!" program that demonstrates unconventional uses of common Rust language features. For example, show how to utilize pattern matching, lifetimes, closures, or concurrency primitives to illustrate Rust’s versatility.
Explain Rust's fundamental types, variable bindings, mutability, and arithmetic operations with straightforward, easy-to-understand code examples. Cover the syntax and semantics of scalar types (integers, floats, characters, booleans) and compound types (tuples, arrays), along with examples demonstrating variable immutability and arithmetic operations.
Delve into the concept of variable immutability in Rust. Distinguish between regular variables, constant variables (
const), and static variables (static). Provide examples to clarify when and why to use each type, considering aspects of performance and memory safety.Use sample code to explain statement selection (using
if,match) and looping constructs (such asfor,while,loop) in Rust. Discuss specific features that enhance Rust's approach to control flow compared to C/C++, such as pattern matching and exhaustive checking.Compare Rust's features related to arrays, raw pointers, and looping with similar features in C++. Examine how Rust’s ownership model, safety guarantees, and pointer types (e.g.,
const T,mut T) differ from C++ and their implications for safe and efficient memory management.As a senior software design engineer, elucidate the concept of user-defined types (UDTs) in Rust. Discuss the benefits of UDTs in Rust relative to C/C++, focusing on enums, structs, and type aliases. Provide examples to demonstrate how these features enhance type safety, clarity, and ease of maintenance.
Explain the design and usage of structures (
struct) in Rust. Discuss why Rust does not use classes like other object-oriented languages and the implications of this design choice. Highlight how Rust achieves encapsulation, polymorphism, and data abstraction through traits and other features instead of classes.Discuss Rust’s enumeration (
enum) features and compare them to enumerations in C++. Explain the advantages and limitations of Rust's enums, including exhaustiveness checking, enum variants with data, and pattern matching, and contrast these with C++ enums.Explore Rust’s modularity features related to compilation. Cover static and dynamic linking, the use of modules (
mod), crates, and the separation of interface and implementation. Discuss the pros and cons of these modularity techniques, including their impact on code organization, reuse, and compilation times.Explain the concept of namespaces in Rust, particularly through the use of modules and the
usekeyword. Compare this system to C++ namespaces, discussing the advantages and limitations of Rust’s approach to namespacing.Discuss Rust's error handling features, including the use of
ResultandOptiontypes, panic mechanisms, and the absence of traditional exceptions. Provide sample code demonstrating how to handle recoverable and unrecoverable errors, and explain how invariants and static assertions (const fn,assert!) contribute to code correctness.Write Rust code to implement a simple calculator that takes a text stream as input. Include the implementation of an abstract syntax tree (AST) and a tokenizer. The calculator should parse and evaluate mathematical expressions, showcasing Rust's capabilities in managing complex data structures and algorithms.
Based on the responses to these prompts, thoroughly review the answers and follow the instructions provided. Ensure that your code runs smoothly in VS Code. Approach this process as if you're leveling up in a game: the more effort you invest, the more you’ll uncover about Rust, and the better your coding skills will become. Don’t be discouraged if you don’t grasp everything immediately; mastering Rust takes practice. Stay persistent, and you will become proficient in Rust in no time. Enjoy the learning journey!
Comments